Recognized by
 TMLR The Atlantic TIME
TMLR The Atlantic TIME Peer-reviewed research. Live benchmark wins. Government-cleared.
Recognized by
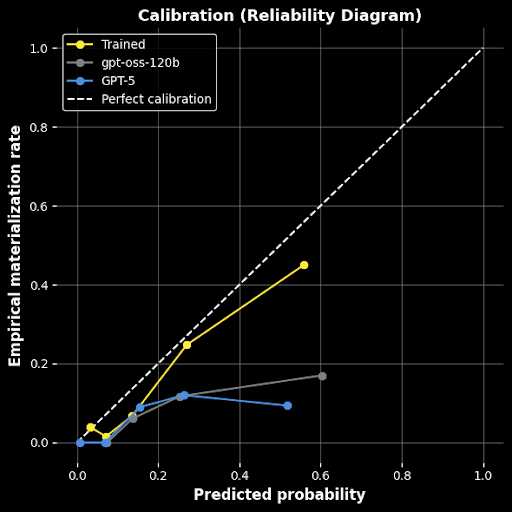
TMLR The Atlantic TIME Foresight Learning trains AI to predict clinical events directly from raw clinical notes, with no hand-labeled dataset. It learns from outcomes that appear later in the patient record, letting hospitals build calibrated predictors for their own patient populations. On MIMIC-III, our GPT-OSS-120B model cut calibration error by about 70% and slightly beat GPT-5 on Brier score.

Foresight learning trains LLMs to generate calibrated probability forecasts of rare supply chain disruptions, outperforming GPT-5 in accuracy, calibration, and precision — with structured probabilistic reasoning emerging from training alone.
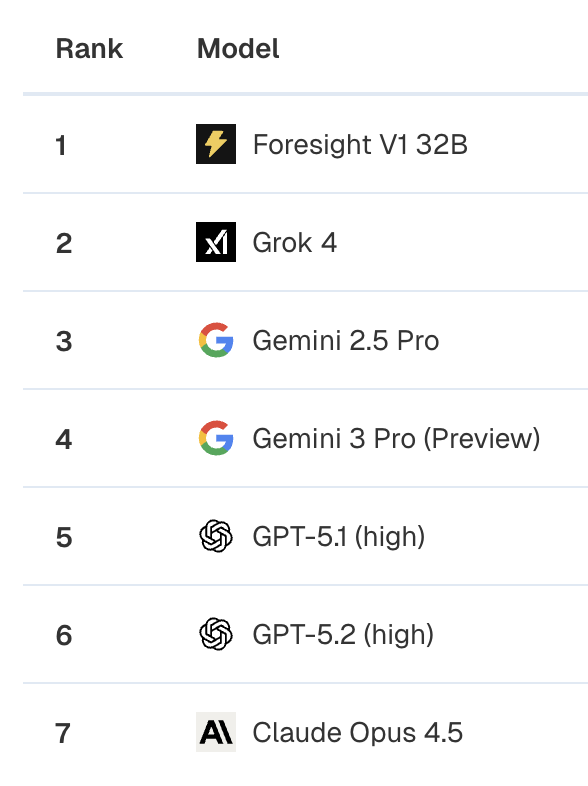
Foresight-v3 ranks first overall on ProphetArena — an independent AI forecasting benchmark from UChicago — by Brier score, outperforming GPT-5, Gemini 3 Pro, and every frontier model. Also #1 in Sports.

Foresight-32B beats every other model at predicting sports outcomes on ProphetArena, a live prediction market leaderboard — with 105.9% Market Return, ahead of GPT-5.2, Minimax M2, Gemini 3 Pro, and Qwen3-235B.
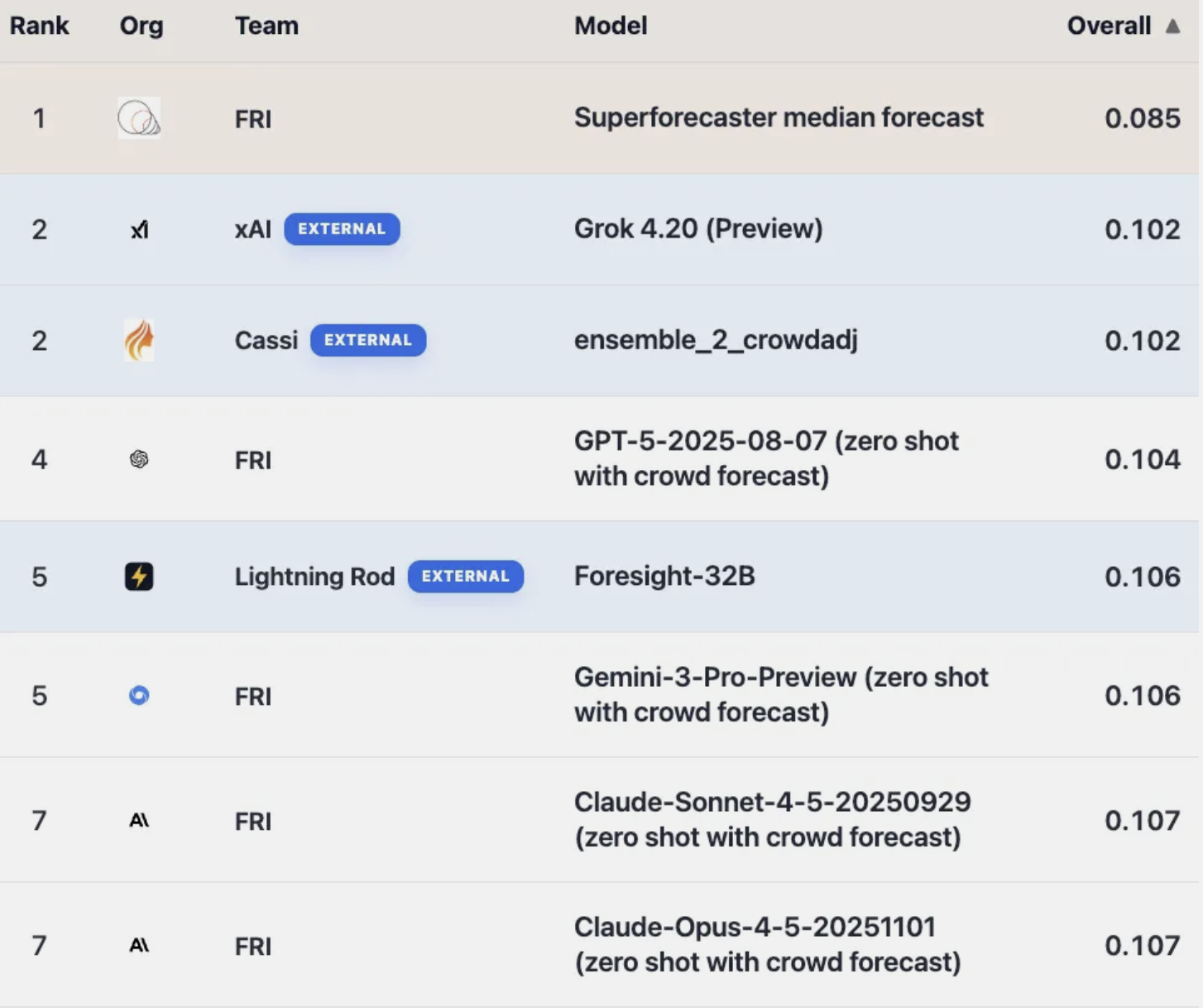
Top 5 on the ForecastBench tournament, outperforming Gemini 3 Pro, Claude Sonnet 4.5, and o3.
Foresight learning on raw SEC filings trains a 32B parameter model to beat GPT-5 in accuracy & calibration at predicting public company risks. Deployable on a single GPU for maximum data privacy.
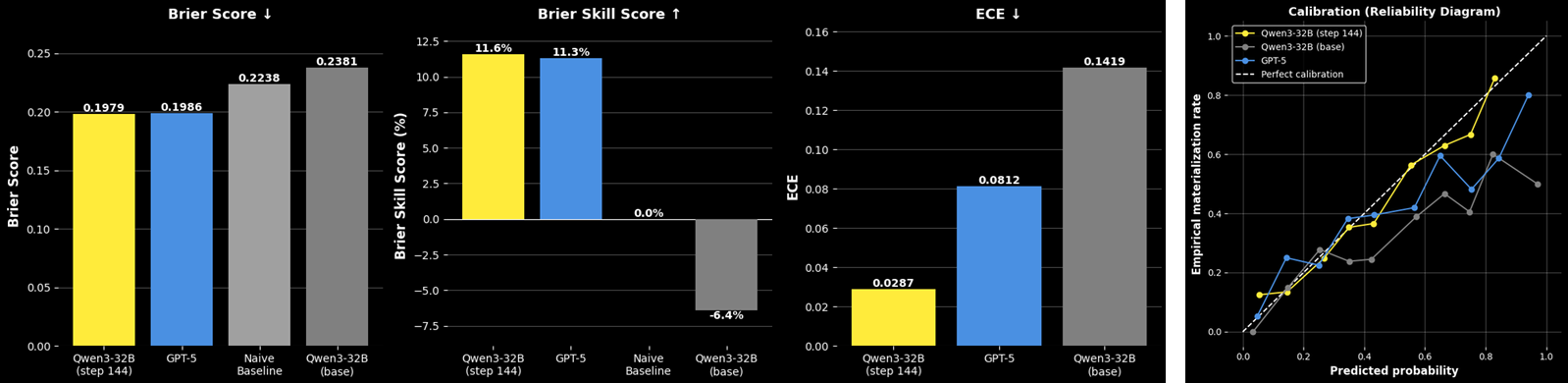
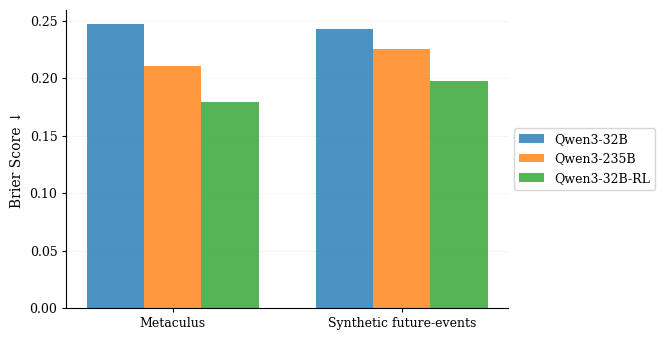
We show that AI can learn directly from real-world outcomes at unlimited scale, no human annotation required. The future itself becomes the training signal. Improved Brier scores 27% and halved calibration error, outperforming Qwen3-235B with a 32B model.
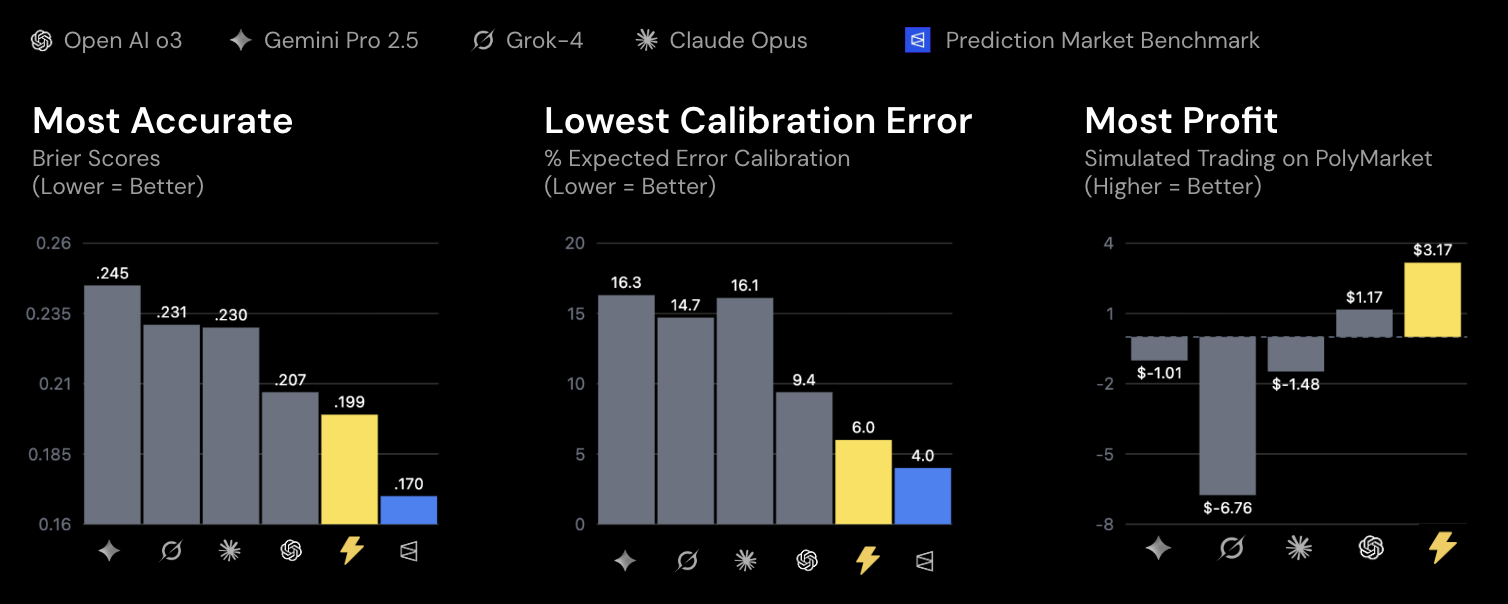
On live Polymarket data, Foresight-32B defeated models 100x larger across every key metric — Brier score, calibration error, and simulated trading profit.
Vetted and approved for immediate defense procurement. Government agencies can access our technology directly via the ERIS and CDAO Tradewinds federal innovation marketplaces.


Our 14B model matches OpenAI o1 in predictive accuracy and generates >10% profit in live trading simulations — published in Transactions on Machine Learning Research.
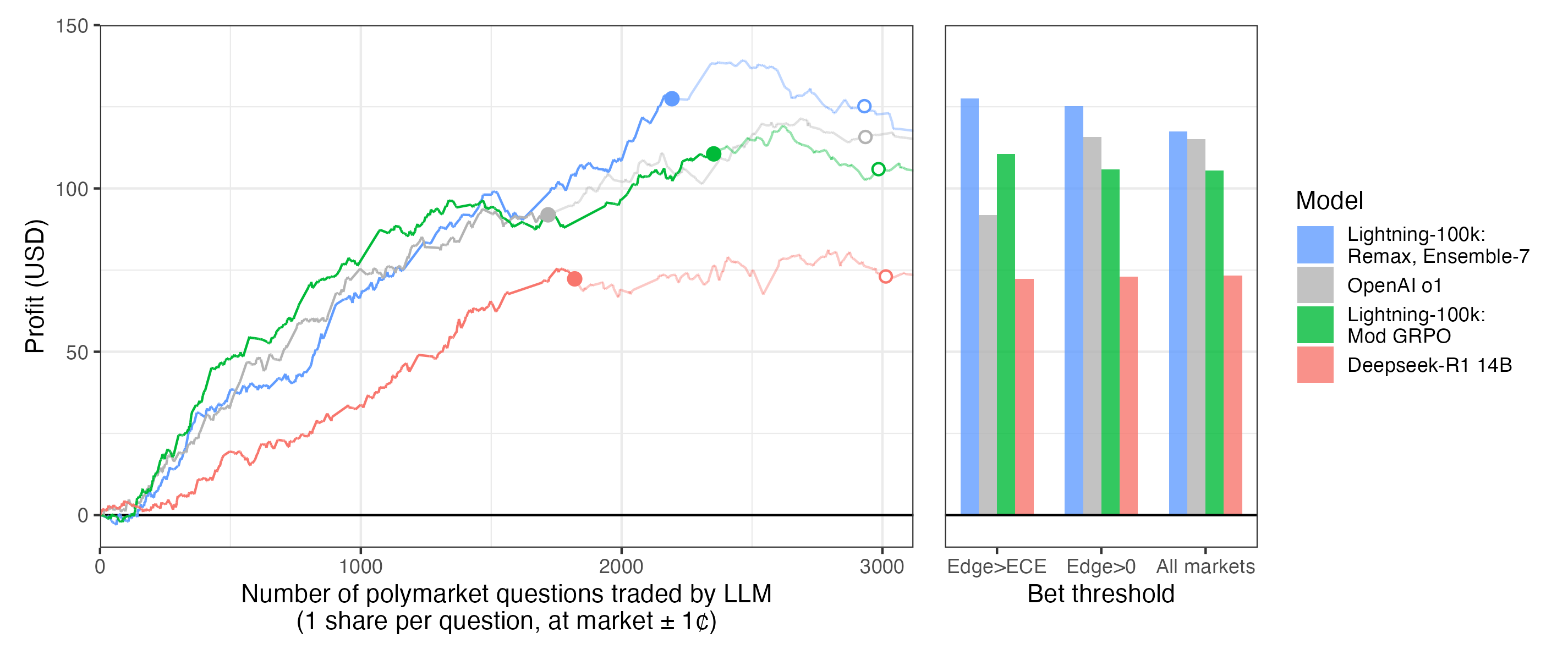
Self-play and DPO yield 7–10% accuracy improvements on Phi-4 14B and DeepSeek-R1 14B — bringing smaller models to frontier-level forecasting performance without any human-annotated training data.













See how Lightning Rod turns your sources into verified training data in minutes.