Example prediction questions
The kinds of questions a model trained on your data can answer.
Key results
Benchmark comparisons against frontier models
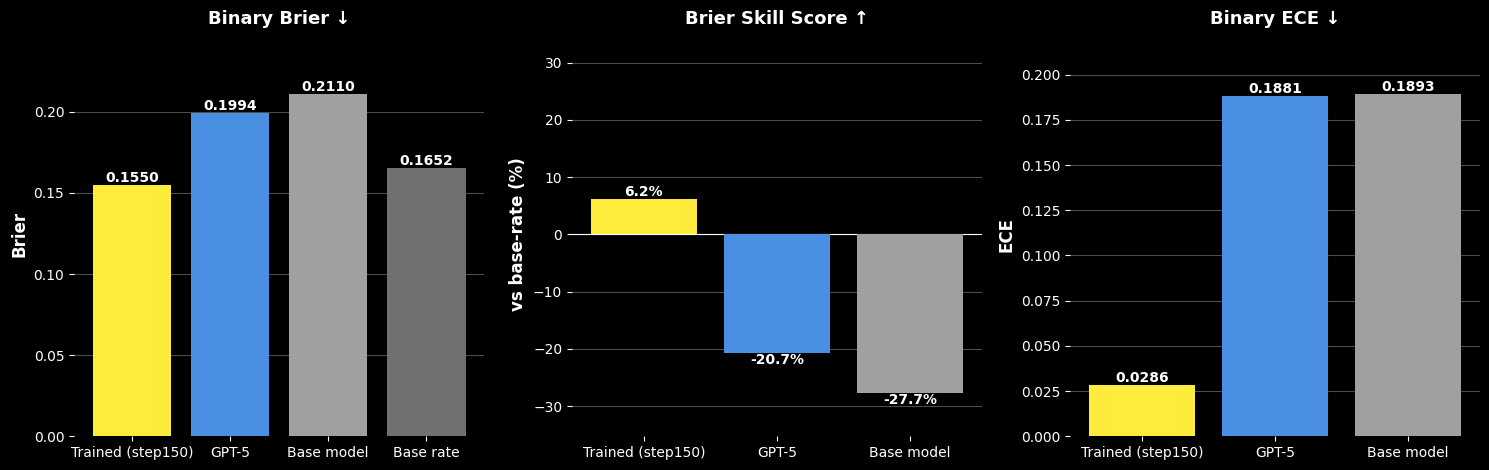
Better Accuracy, Skill, and Calibration vs. GPT-5
Trained on Fed Beige Book narratives, Foresight posts a Brier score of 0.155 vs. 0.199 for GPT-5 and 0.211 for the base model — a 22% reduction in error. It is the only model to beat the base rate (Brier Skill Score +6.2% vs. −20.7% for GPT-5 and −27.7% for the base model), and cuts calibration error (ECE) by ~6× vs. GPT-5.
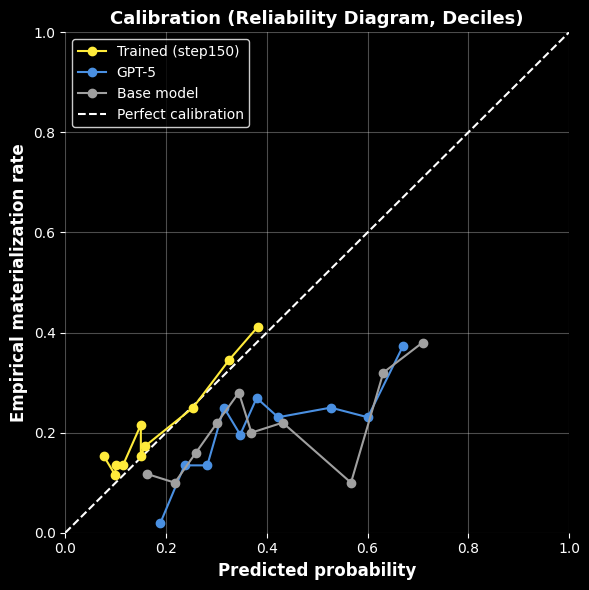
Calibration Reliability Diagram
On the reliability diagram, Foresight (yellow) hugs the perfect-calibration diagonal across deciles — when it says 30%, roughly 30% of events materialize. GPT-5 and the base model are systematically overconfident, drifting well below the line at higher predicted probabilities. For macro decisions where the magnitude of a probability drives sizing and hedging, calibrated outputs are the difference between actionable signal and noise.
Explore
Primary write-ups and artifacts for this solution.