Example prediction questions
The kinds of questions a model trained on your data can answer.
DATASET Market outcomes
RL
Question
Will the US Fed cut rates by more than 25bps before end of Q3?
Question source
Wall Street Journal Jun 12, 2025
Fed officials signal openness to larger cuts if labor market softens
Label
No.
Type
binary
Confidence
Label source
Federal Reserve Sep 30, 2025
FOMC statement: 25 basis point reduction in target range
Key results
Benchmark comparisons against frontier models
ProphetArena Overall Leaderboard
Foresight V3 holds the #1 spot on ProphetArena's live benchmark, ahead of Gemini 3 Pro and GPT-5.2 — while being 10–100× smaller than the frontier models it beats.

Live Polymarket Benchmark
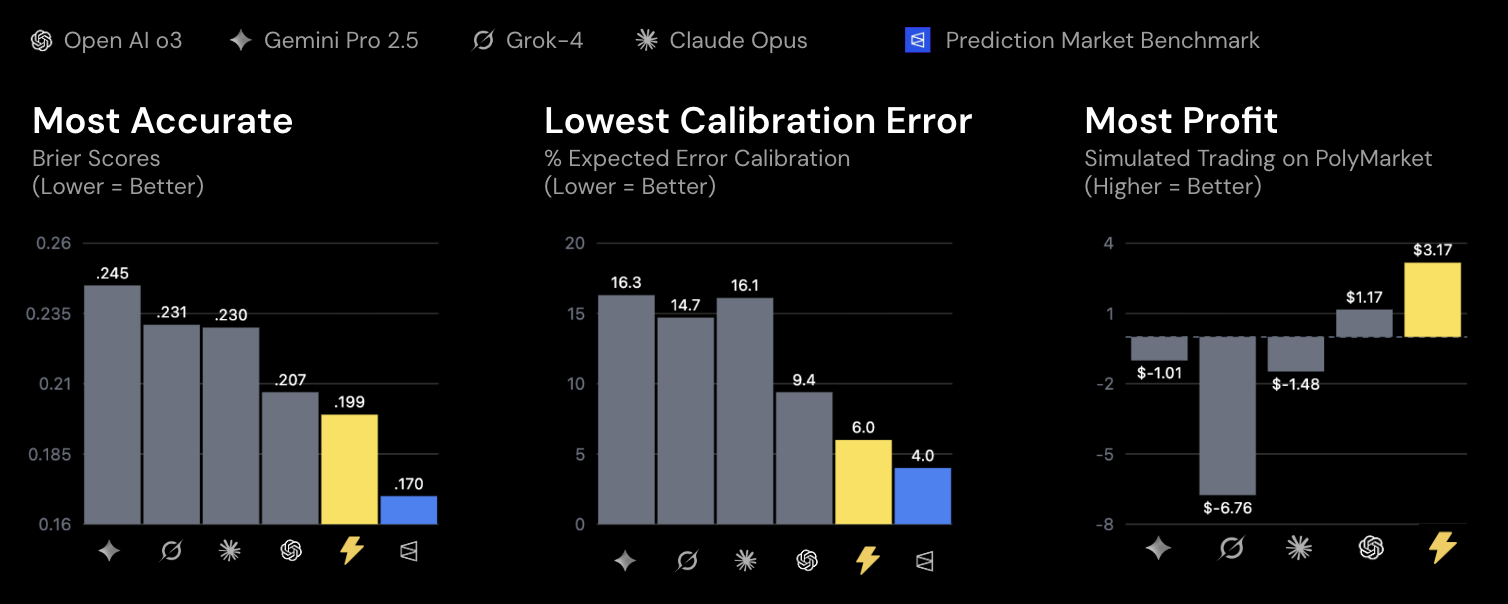
On 251 live Polymarket questions, Foresight-32B achieved Brier score 0.199 vs. GPT-5's 0.207 — with 69% lower calibration error (ECE 6.0% vs. 16.1%) and positive simulated trading profit while frontier models lost money.
Explore
Primary write-ups and artifacts for this solution.